卷积神经网络
一、图像模式的特征
- 平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为"平移不变性"。
- 局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是"局部性"原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
- 缩放一致:图像的大小不改变局部特征,在神经网络逐层累加的过程中,可以直接对图像进行缩放,然后提取特征。
根据以上特点,在图像识别任务中,采用卷积层和池化层来检测目标图像和对图像进行缩放,可以避免全连接层所需的大量计算。
二、卷积
在数学中,两个函数(比如 : )之间的"卷积"被定义为
也就是说,卷积是当把一个函数"翻转"并移位 时,测量 和 之间的重叠。当为离散对象时,积分就变成求和。例如,对于由索引为 的、平方可和的、无限维向量集合中抽取的向量,我们得到以下定义:
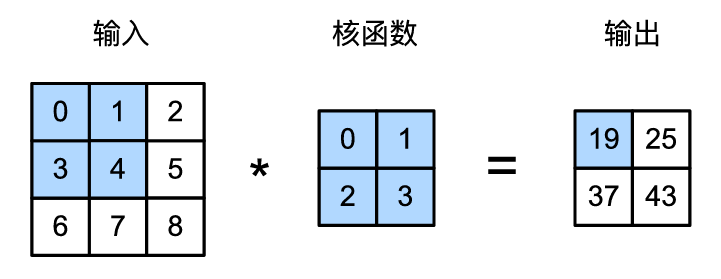
对于二维张量,则为 的索引 和 的索引 上的对应加和:
然而,卷积层进行的运算是互相关运算,而不是卷积运算,即不需要对二维张量进行翻转:
三、CNN网络结构

1、输入层
在卷积神经网络中,如果图像为一张灰度图像,那么输入层就为一个 的二维张量;如果需要处理彩色图像,那么就需要增加通道数,例如标准的RGB图像具有代表红、绿和蓝的三个通道,输入层就为 。
2、卷积核
在卷积层中,卷积核相当于滤波器,将图像的边缘特征提取出来,从而判断物体的类别。
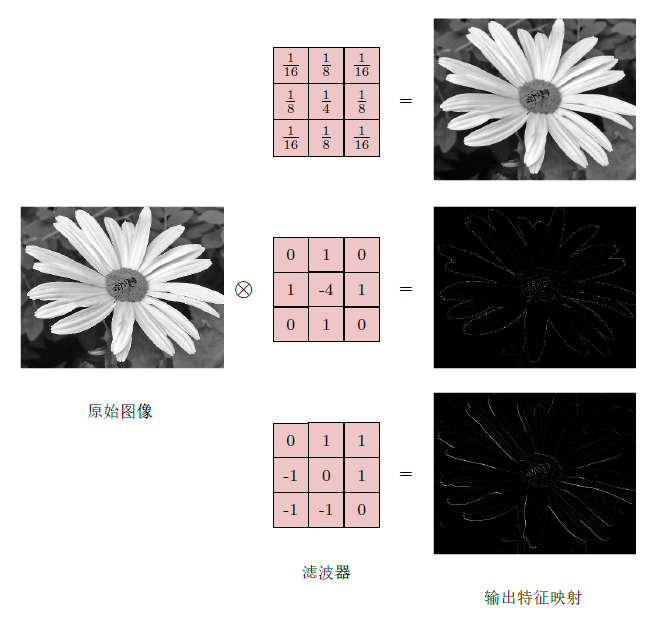
高度和宽度分别为 和 的卷积核可以被称为 卷积或 卷积核。
多输入通道:
对于灰度图像,仅需要单通道卷积核;当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为 ,那么卷积核的输入通道数也需要为 。
当 时,我们卷积核的每个输入通道将包含形状为 的张量。将这些张量 连结在一起可以得到形状为 的卷积核。由于输入和卷积核都有 个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将 的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
多输出通道:
在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
用 和 分别表示输入和输出通道的数目,在一个卷积层中,我们可以采用多个不同的卷积核,提取多种不同模式的特征。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为 的卷积核张量,这样卷积核的形状是 。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
卷积核:
卷积,即 ,看起来似乎没有多大意义。毕竟,卷积的本质是有效提取相邻像素间的相关特征,而 卷积显然没有此作用。尽管如此, 仍然十分流行,经常包含在复杂深层网络的设计中。
下图展示了使用 卷积核与 3 个输入通道和 2 个输出通道的互相关计算。这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。我们可以将 卷积层看作在每个像素位置应用的全连接层,以 个输入值转换为 个输出值。因为这仍然是一个卷积层,所以跨像素的权重是一致的。同时, 卷积层需要的权重维度为 ,再额外加上一个偏置。可见 卷积通常用于调整网络层的通道数量和控制模型复杂性。
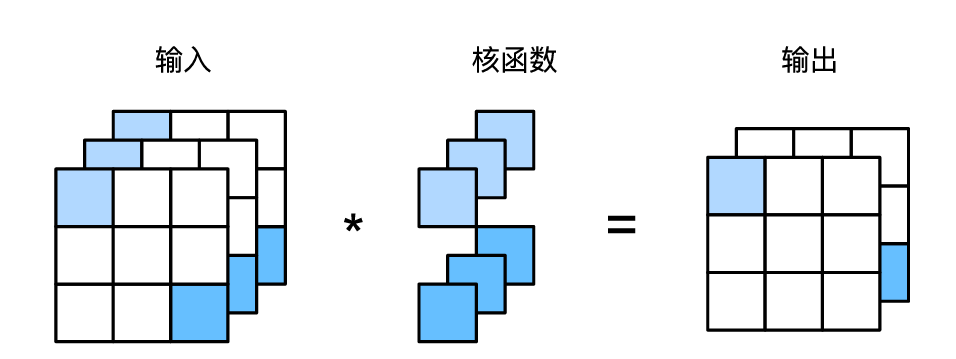
3、卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。就像我们之前随机初始化全连接层一样,在训练基于卷积层的模型时,我们也随机初始化卷积核权重。
假设输入形状为 ,卷积核形状为 ,那么输出形状将是 。因此,卷积的输出形状取决于输入形状和卷积核的形状。除此之外,填充和步长也会影响输出的形状。
填充(padding):
如上所述,在应用多层卷积时,我们常常丢失边缘像素。由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。但随着我们应用许多连续卷积层,累积丢失的像素数就多了。解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是 0 )。例如,我们将 的输入填充到 ,对于 的卷积核,那么它的输出就增加为 。
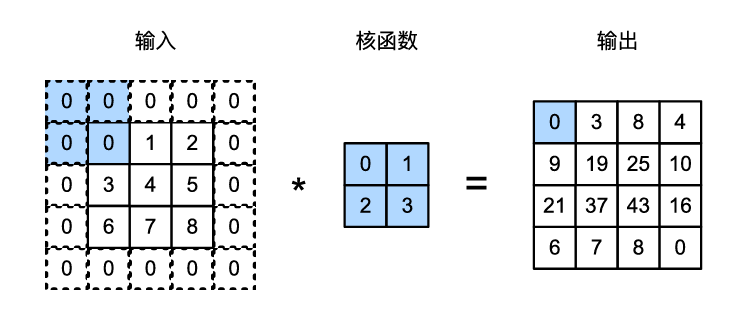
在许多情况下,我们需要设置 和 ,使输入和输出具有相同的高度和宽度。这样可以在构建网络时更容易地预测每个图层的输出形状。假设 是奇数,我们将在高度的两侧填充 行。因此,卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
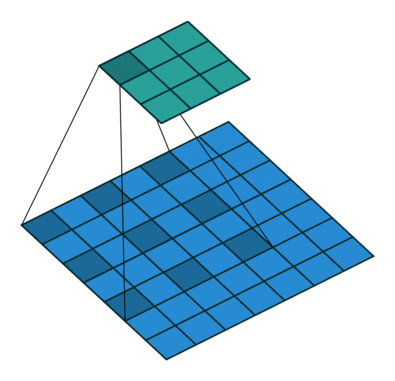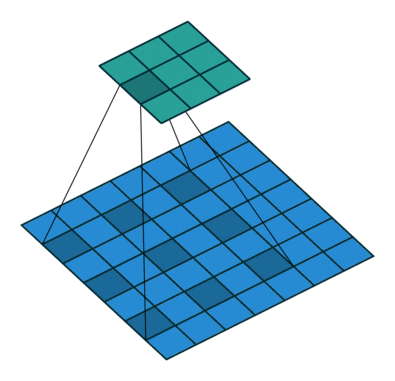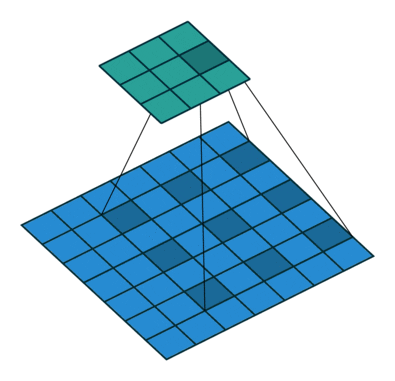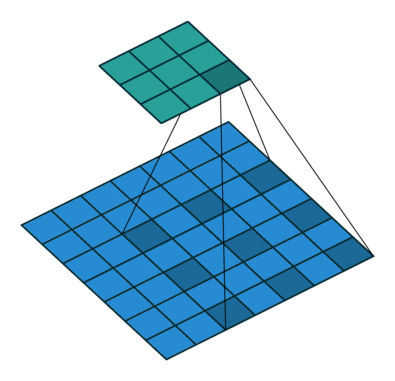
步长(stride):
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。在前面的例子中,我们默认每次滑动一个元素。但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
下图是垂直步幅为 3 ,水平步幅为 2 的二维互相关运算。着色部分是输出元素以及用于输出计算的输入和内核张量元素。
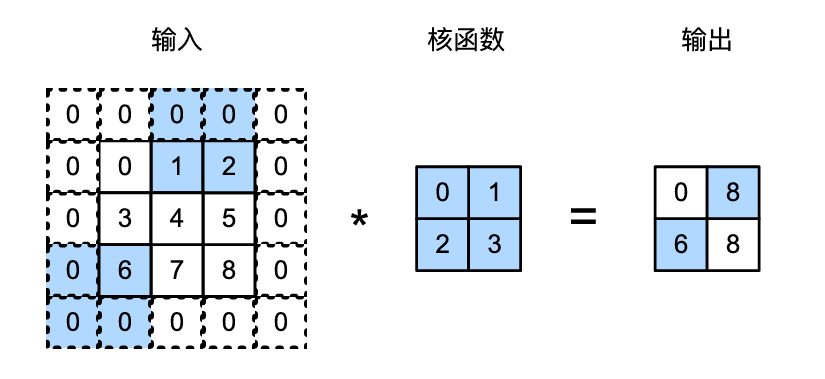
可以看到,为了计算输出中第一列的第二个元素和第一行的第二个元素,卷积窗口分别向下滑动三行和向右滑动两列。但是,当卷积窗口继续向右滑动两列时,没有输出,因为输入元素无法填充窗口(除非我们添加另一列填充)。
通常,当垂直步幅为 、水平步幅为 时,输出形状为。
如果我们设置了 和 ,则输出形状将简化为 $$\left\lfloor\left(n_{h}+s_{h}-1\right) / s_{h}\right\rfloor \times\left\lfloor\left(n_{w}+s_{w}-1\right) / s_{w}\right\rfloor$$ 更进一步,如果输入的高度和宽度可以被垂直和水平步幅整除,则输出形状将为 。
为了简洁起见,当输入高度和宽度两侧的填充数量分别为 和 时,我们称之为填充 。同理,当高度和宽度上的步幅分别为 和 时,我们称之为步幅 。默认情况下,填充为 0 ,步幅为 1 。在实践中,我们很少使用不一致的步幅或填充,也就是说,我们通常有 和 。
4、激活层

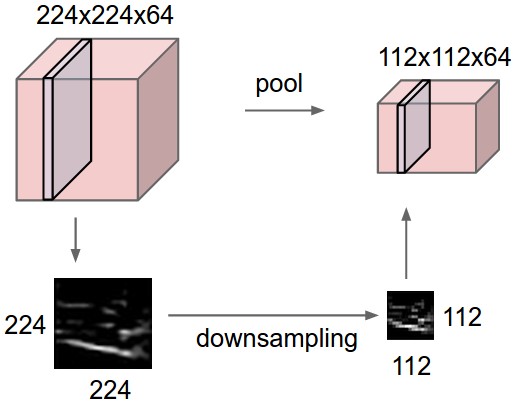
5、池化层(汇聚层)
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野就越大。
目标检测任务通常会跟全局图像的问题有关(例如,"图像是否包含一只猫呢?"),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
Similarly, in object detection, a small receptive field may not be able to recognize large objects.
同样,在目标检测中,一个小的感受野可能无法识别较大的目标。

在上面的图片中,如果神经网络的感受野是绿色的框,那么这辆汽车可能就无法被检测到。通过池化层可以将图像缩小,扩大感受野。
此外,当检测较底层的特征时,我们通常希望这些特征保持某种程度上的平移不变性。例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即 ,则新图像Z的输出可能大不相同。而在现实中,随着拍摄角度的移动,任何物体几乎不可能发生在同一像素上。即使用三脚架拍摄一个静止的物体,由于快门的移动而引起的相机振动,可能会使所有物体左右移动一个像素(除了高端相机配备了特殊功能来解决这个问题)。
池化层的两个主要作用:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
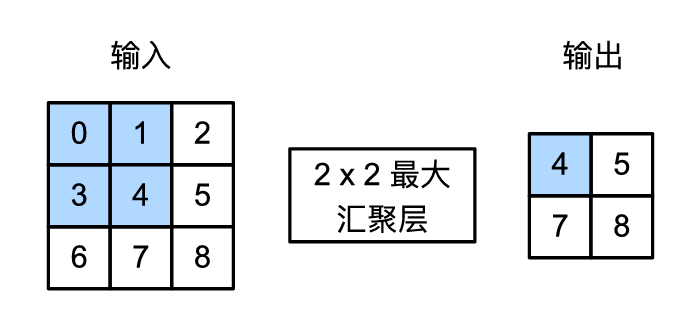
与卷积层类似,池化层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。
对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值。与卷积层一样,汇聚层也可以改变输出形状。默认情况下,池化层的步长与池化窗口的形状一致。我们可以通过填充和步幅以获得所需的输出形状。使用最大汇聚层以及大于 1 的步幅,可减少空间维度(如高度和宽度),相当于缩小图像。
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。这意味着汇聚层的输出通道数与输入通道数相同。
6、全连接层
特征提取后,我们需要将数据分类为不同的类别,这可以使用完全连接的神经网络来完成。
7、感受野
在卷积神经网络中,对于某一层的任意元素 ,其感受野(receptive field)是指在前向传播期间可能影响 计算的所有元素(来自所有先前层)。
感受野可能大于输入的实际大小。让我们用下图为例来解释感受野:给定 卷积核,阴影输出元素值 19 的感受野是输入阴影部分的四个元素。假设之前输出为 ,其大小为 ,现在我们在其后附加一个卷积层,该卷积层以 为输入,输出单个元素 。在这种情况下, 上的 的感受野包括 的所有四个元素,而输入的感受野包括最初所有九个输入元素。因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。
感受野的计算:
卷积层和池化层都会影响感受野,而激活函数层通常对于感受野没有影响,当前层的步长并不影响当前层的感受野,感受野和填充没有关系,计算当层感受野的公式如下:
其中, 表示当前层的感受野, 表示上一层的感受野, 表示卷积核的大小, 表示之前所有层的步长的乘积(不包括本层)。
如何增大卷积网络的感受野:
- 添加更多卷积层 (使网络更深)
这个方法对感受野的增大是线性的,因为每增加一层,感受野大小就增加一个核大小。此外,实验证实,随着理论感受野的增加,但有效感受野在减小。RF 指的是感受野,ERF 指的是有效感受野。

- 添加池化层或更高步长的卷积 (下采样)
像池化这样的下采样技术,可以成倍增加感受野大小。ResNet 等现代架构结合了这些技术。 - 使用空洞卷积(Dilated Convolutions)
按顺序放置空洞卷积,可以指数级地增加感受野。本质上,空洞卷积引入了另一个参数,记为 ,称为扩张速率。扩张在卷积核中引入了 ”孔洞“。这些 “孔洞” 基本上定义了核值之间的间隔。因此,虽然核中的权重数量保持不变,但这些权重不再应用于空间相邻的样本。
- 增大卷积核的大小

